 An Introduction to Taiwanese Speech Notepad
Chinese version
An Introduction to Taiwanese Speech Notepad
Chinese version
Taiwanese Speech Notepad
An Application Software of Vikon Multilingual Text to Speech System Compiler
Yu-Chu Chang, Tung-Ying Chang
2000-2009
Software Download (If you cannot download from the cloud, please contact the author by e-mail.)
Although there is still room for improvement, the functionality of the 2021 version of the Taiwanese Speech Notepad has already reached the goal set in 1998. I present this software, which has been developed for many years, to people like me who want to read Taiwanese articles and learn to write Taiwanese. I hope it will be helpful to their learning, and everyone is welcome to provide suggestions for improvement. Users who have downloaded the old version of the installation file, please download the updated version, unzip it and copy the file to the default working directory c:\TSN-TRO\ or the working directory of the Taiwanese Speech Notepad specified during installation.
Taiwanese Speech Notepad software installation file download
Taiwanese Speech Notepad Update File Download
Multimedia video display
Taiwanese Audio Works Showcase
General Introduction
Taiwanese Speech Notepad, a stand-alone text-to-speech software for the person who likes to learn Taiwanese language through Romanized Taiwanese or Chinese characters registered copyright with the name of Modern Literal Taiwanese Reading and Writing System in 2001. Since Taiwanese tone group parser, the speech engine and the speech synthesizer are original programs developed by the authors, the system can work independently without mounting MS Speech SDK or IBM TTS Engine. With Corpus-based multilingual dictionary and Dynamic Database structure, the speech of Taiwanese Speech Notepad can be generated from literal Romanized Taiwanese or Chinese text using pre-recorded natural human voice as well as prosodic speech synthesizer. Taking an article with 692 Taiwanese words as an example, the output voice is 338 seconds, which takes 10 seconds. Input an article with 1711 Taiwanese words, and the output voice is 890 seconds, which takes 25 seconds. On average, about 33 seconds of speech can be synthesized per second.
Taiwanese is a phonetics-based language. A Taiwanese sentence is a Set (mathematics), a collection of well defined and distinct objects named tone group. There are two different tones for a syllable or a word in Taiwanese. In initial or medial position of a word or a tone group, the syllable or word will be given with sandhi tone while lexical tone was given for the end syllable of a word or a tone group. Therefore, if and only if a lexical tone was given at the end of a set of words, then the set of words was a tone group.
Tone sandhi is a phonological change occurring in tonal languages such as Mandarin and some languages spoken in China, in which individual word change its tone that was based on the pronunciation of adjacent words in a sentence. Tone sandhi of Taiwanese, although complex, can be followed by some rules. In addition, tones, semantics and syntactic structures are closely connected in Taiwanese. A listener can distinguish exactly word meaning from its tone phase among similar sentences. For example, different tone phase of the clay oven roll represented distinct meaning in the following sentences.
Mua5-a2 (lexical tone) tua7 e5 sio-piann2. (The clay oven roll with big sesame.)
Mua5-a2 (context tone) tua7 e5 sio-piann2. (The clay oven roll as big as a sesame.)
Another example is that the tone phase of "tsit4-king (the unit of a house)" depends on its context in a sentence.
Tsit4-king (lexical tone) u7 tsai-hue. (There are flowers around the house.)
Tsit4-king (context tone) u7 tsai-hue e5 tshu3 si7 guan2-tau. (The house with many flowers is mine.)
In general, inserting words in a Taiwanese sentence could be a lexical form, a context form or a tone group. No matter what embedding form is, the final sentence structure would be decomposed into tone groups.
The following sentences reveal the unique tone group derivative structure of Taiwanese language through variety forms of word inserting within a sentence.
The original sentence consists of two tone groups: [A-bi2] [beh khi3 Tai5-pak.] (Amy is going to Taipei.)
Context word (siunn7) inserting: [A-bi2] [siunn7 beh khi3 Tai5-pak.] (Amy wants to go to Taipei.) The number of tone group doesn't change.
Lexical word (pai3-it) inserting: [A-bi2] [pai3-it] [beh khi3 Tai5-pak.] (Amy is going to Taipei on Monday.) The number of tone group was changed to three.
Tone group (tse7 gu5-tshia) inserting: [A-bi2] [beh tse7 gu5-tshia] [khi3 Tai5-pak.] (Amy is going to Taipei by an ox-cart.) The number of tone group was changed to three.
Since tone sandhi processing is so important to Taiwanese sentences that the tone group parser will surely be one of the most complicated and challenged subjects for Taiwanese text-to-speech systems. There are three major components in Taiwanese Speech notepad; a tone group parser, a speech synthesizer and a speech engine. In general, the implementation of speech synthesizer or speech engine depends on programming technique. However the tone group parser relies more on knowledge representation method and the application of artificial intelligence. Luckily we find a way to extract linguistic expertise from human experts and transfer it into an well-organized knowledge base. A symbol system that was designed to coin language expertise and heuristic knowledge was hooped to a corpus. Each symbol consist of three attributes: default tone value, part of speech and mode mark. This corpus was used to cooperate with rule based sandhi processor to pick up accuracy tone among possible tones for each word in a sentence. By means of the symbol system and rule inference homonyms or multiple-POS words such as ti7 or be2 in the following sentences can be assigned accuracy tone through tone sandhi processing.
Ti7 (chopstick, noun, lexical tone) khng3 ti7 (at/on/in, preposition, context tone) ann2-na5-a2 lai7. (The chopsticks were in a bowl basket.)
Tsit-tsiah be2 (horsae, noun, lexical tone) be2 (buy, verb, context tone) beh kah goo7-ban7. (The horse was bought for 50000 bucks.)
Through the study of Taiwanese architecture, we realize that the production system of Taiwanese is quite clear and definite. This logical and scientific natural language has been developed and inherited several thousand years without its own writing system. Tone group must be one the most important elements for Taiwanese language acquisition. Through the development of Taiwanese Speech Notepad, we found that the rules of tone sandhi are simple and universal in word-level while a knowledge representation method can be used to infer tone phase among words in a sentence and define tone group explicitly. Tone group was not only the basic syntax unit of a sentence but also a unique semantic unit as well as prosodic boundary in Taiwanese. This approach may reveal that modern Mandarin that lack of the regularity of tone group is different from Taiwanese language.
Taiwanese Speech Notepad is more than a text-to-speech system. It is also a simulator for tone sandhi acquisition in Taiwanese intra-sentence. By means of the adjustment of corpus and rules, we may understand how people handle Taiwanese tone sandhi through long-term memory as well as short-term memory in our brain. In other words, the Taiwanese tone group parser based on languages learning and acquisition theory offered an experimental environment for the simulation of knowledge engineering and human thinking. The forming process and the derivative structure of Taiwanese probably is one of the keys to artificial intelligence research.
(Official Romanized Taiwanese Demo)
The followings are three speech output samples.
 On an Ox cart
The story of a sundress
A Watermelon in January
On an Ox cart
The story of a sundress
A Watermelon in January
Text Parsing and Speech Synthesis
Each sentence of the input text is analyzed and decomposed into phrases, words, or syllables through corpus-base dictionary and text parser. Special text such as dates and numbers are converted into readable text before parsing. A high performance searching engine was designed to retrieve speech data and distribute pre-recorded Voice to speech buffer. Word without pre-recorded that determined based on searching result is derived into syllables and is then
merged with speech synthesizer. A rule-based inference mechanism was designed to decide tone for each
word in the sentence during speech merging process. Another procedure was used to restrain fixed tone prior to apply
rule-based inference. This process makes tone sandhi within Taiwanese sentence possible and efficient.
Media Language
Taiwanese Speech Notepad has already developed text-to-speech versions for POJ (??|u???r),
MLT/TMSS (?{?N????) and Official Romanized Taiwanese (??|???xu) spelling system since 2000. Special Romanized Japanese
and English words are also available to be used in Taiwanese sentences. A media language was created to
convert words, phrases and sentences from different Taiwanese spelling systems into the same speeches.
All versions are compiled with a language-independent software - Vikon Multilingual Text to Speech System (MLTTS)
Compiler for the purpose of fast and effective performance. Tools and programs are developed and constantly
being improved to implement and support new languages.
Components and relational frame structure
1. Online manual
2. File manager (9,11,14,16)
3. Voice selector (17,18)
4. Speech engine (13,15,16,17)
5. Taiwanese text translator (19,16)
6. On/Off switch for word translation (13,16)
7. Speaker switch (4)
8. Chinese text translator (15,16)
9. Taiwanese word processor (8,12,13,15,16,17)
10. Word translator (13,16)
11. Chinese word processor (5,12,16,19)
12. Multilingual dictionary (4,5,8,13,14,16)
13. Word sensor (10,16)
14. Digital recorder (2,16)
15. Text parser (4,9,17)
16. Data manager (4,5,8,9,10,11,12,13,14,17,18,19,20)
17. Speech synthesizer (4,9,15,16,18)
18. Binary data processor (16)
19. Prime database (5,11,16)
20. Format converter (16)
21. External application program speech output interface (4)
22. Rule-base inference engine (12,16,17,19)
23. Index builder (12,16)
24. Spelling checker (12,16,19)
25. Speech converter (4,6,13,16,17,20)
26. Code converter (2,21)
External application program interface
In order to apply our most sophisticated text-to-speech modules in a variety of way, an external application
program interface was designed for users while they are using word processor, Internet browser,
or writing an E-mail. Yes, users can hear the voice when they highlight text and click speech output icon
(What You See Is What You Hear). We have also developed several highly efficient algorithms for coinage
in our text-to-speech system.
Main features
Word translation between Taiwanese and Chinese
Sentence translation between Taiwanese and Chinese
English and Chinese translation by simply moving a mouse cursor over word in Taiwanese window
English and Taiwanese translation by highlighting Chinese word in Chinese window
Taiwanese audio dictionary browsing
Taiwanese spell-checking and speech output
Taiwanese/Chinese/English dictionary browsing and synchronic sample sentences acquisition (Official Romanized Taiwanese Demo )
Text Input, output, editing and text-to-speech file saving (Taiwanese audio book maker)
Taiwanese speech output for Internet browsers (Official Romanized Taiwanese Demo) and external program (Official Romanized Taiwanese Demo )
Taiwanese word searching with English/Chinese input (Official Romanized Taiwanese Demo )
Taiwanese ASCII/Unicode format conversion
(Official Romanized Taiwanese Demo)?C
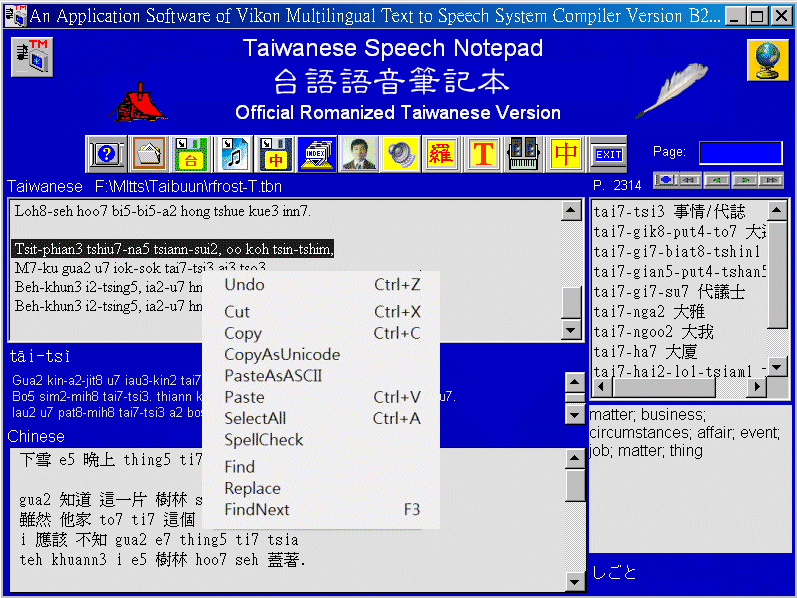
The main frame of Taiwanese Speech Notepad for Official Romanized Taiwanese
Click here to hear Taiwanese speech output of
Stopping by Woods on a Snowy Evening - by Robert Frost
Kernel Technology
The developed system was based on the following software and related research during the past years (see References)
1. Natural Language Process and Machine Translation (1984-1986)
Representation of meaning, conceptual analysis, scripts indexing, binary decision tree research.
2. Dynamic Database (1984-1988)
Word processor and data processing, three-dimensional dynamic data structure design, data indexing and searching, the implementation of database system.
3. Expert System and Inference Engine (1987-1991)
The development technique of knowledge representation, rule-based inference engine design, multimedia integration, the implementation of knowledge base and expert system.
4. Semantic Net Construction and Frame Structure Design (1987-
Semantic analysis, commonsense deductions, knowledge representation, frame structure design, the implementation of object-oriented and functional driven design programming.
5. Graphic User Interface (1992-1993)
Mouse-driven and coordinates detection, graphic decoding and presentation, sound playing and the implementation of external programs interface.
6. Speech, Video process and Multimedia Management (1992-1998)
Sound and graphic processing, fonts mapping, animation picture design, graphic acquisition, pattern recognition, the implementation of multimedia editor and tutorial system.
7. Speech Engine and Speech Synthesizer Design (1998-2001)
Mass data processing, linguistic material acquisition, parser design, syllables cutting and synthesis, words indexing, spelling checking, character detection, the implementation of Chinese and Taiwanese text-to-speech systems.
8. Corpus Construction (1998-
Multi-language dictionary and corpus design, linguistic material collection and transformation, the integration of linguistic expertise and heuristic knowledge.
9. Text-to-speech Compiler Implementation (2001-2005)
The integration of function test for Text-to-speech system, the extraction of linguistic material, external application program speech output interface design, code switching, the implementation of Text-to-speech compiler.
10. Speech Model training and Recognition (2005-
The promotion of Hidden Markov model, pitch detection, tone comparison, syllables recognition, the implementation of Taiwanese speech recognition.
11. Auto-feedback and Machine Learning (2006-
Information feedback, the integration of linguistic expertise and logic inference.
12. Language Model and Cognitive Simulation (2008-
The experiment of semi-automated simulation for machine learning, the implementation of Taiwanese language model.
Main Operating Frame
There are four windows in main operating frame; Taiwanese window, Chinese window, online dictionary window and sample sentences window. Another area can also show Unicode Taiwanese, Chinese, English and Japanese words when mouse was moved over Taiwanese word, highlight Chinese word or dictionary word. Right click mouse button brought a menu list for Undo, Copy, Cut, Paste, SelectAll, Find, Replace and FindNext operations. Additional operations such as CopyAsUnicode, PasteAsASCII and SpellCheck are also available in Taiwanese window. CopyAsUnicode will convert ASCII Taiwanese into Unicode Taiwanese (symbol tone mark) for external application programs. PasteAsASCII will convert Unicode Taiwanese into ASCII Taiwanese. For any highlight text in Taiwanese window, a spell-checker can be executed after click SpellCheck operation. Illegal Taiwanese words will be showed in red. Words that are not built in main dictionary will be showed in blue.
Graphic User Interface
 External Application Program Speech Output Interface
External Application Program Speech Output Interface
Click left mouse key to open
 Speech Output Interface
Speech Output Interface
In an external program such as word processor or Internet browser, user can highlight the text and click Speech Output icon. All Taiwanese text in ASCII, Unicode and Big-5 will be transferred into speech output.
User can also click right mouse and select "Paste" in Taiwanese window to import highlighted Taiwanese text from external program during speech output (Official Romanized Taiwanese Demo ).
Another way for the conversion of Taiwanese Unicode -> ASCII :
Step 1, click right mouse on  , then click left mouse on
, then click left mouse on 
Step 2, move mouse to Taiwanese window and click right mouse, select "Paste" in Taiwanese window,
highlighted Unicode Taiwanese will be converted into ASCII text and pasted to the cursor position.
 Taiwanese Word Searching
Taiwanese Word Searching
All the Taiwanese words in main dictionary can be searched with English/Chinese. Speech output is also available for highlighted searching result (Taiwanese word).
 Help
Help
Show Help-page.
 Open Taiwanese/Chinese File
Open Taiwanese/Chinese File
Open Taiwanese file: Click mouse key in Taiwanese window and move the mouse to click this icon.
Open Chinese file: Click mouse key in Chinese window and move the mouse to click this icon.
 Save Taiwanese Files
Save Taiwanese Files
Save all text in Taiwanese windows to an ASCII plain text file and a Unicode symbol code file.
 Save Speech Files
Save Speech Files
For any part of an input text, an audio file can be saved during speech output process. This function offers an efficient way to produce audio books.
 Save Chinese File
Save Chinese File
Save all text in Chinese windows to a Big-5 code file
 Voice Selection
Voice Selection
Users can choose men's voices, women's voices or boys' voices for speech output.
Only Man's voice in current version.
Speech Output
Turn the highlighted text into speech output. Click right key to select reading speed (tempo).
 Chinese/Romanized Taiwanese Translator
Chinese/Romanized Taiwanese Translator
Highlighted text in Chinese window will be translated to Romanized Taiwanese in Taiwanese window.
 Word over Mouse Cursor on/off Switch
Word over Mouse Cursor on/off Switch
Function on:
Whenever users browse the text in Taiwanese window and come across a word, users could move mouse/cursor over that word, the system would translate it into Chinese and English immediately.
The dictionary window will show the word on the top simultaneously.
Function off:
In Taiwanese window, users can type a Taiwanese word and listen to the speech immediately after pressing the space bar.
In Chinese window, users can type a Chinese character and listen to the speech immediately.
 Speaker on/off Switch
Speaker on/off Switch
The on/off switch of speakers
 Romanized Taiwanese/Chinese Translator
Romanized Taiwanese/Chinese Translator
Highlighted text in Taiwanese window will be translated to Chinese in Chinese window.
 Exit Program
Exit Program
Exit program and show the reminder for unsaved text.
Download TSN update file (for 64 bit computer register users only)
Please decompress update file and copy all the files to the default directory (c:\tsn-tro\) or the directory that you installed Taiwanese Speech Notepad.
[ Works in Taiwanese | Homepage
| Taiwanese Tone Group Parser
]
This website is sponsored
by VIKON Corp.
Copyright July 1996.
All rights reserved.
Last update : 2015-04-25
Any comment ? Mail to:
 ?@
vikontony@gmail.com
?@
vikontony@gmail.com